Algorithm Development
Algorithm
Development
Data Cleaning and Preparation
Data and Edge Case Management
Algorithm Testing and Training
From automated data preprocessing to efficient scene data management and large-scale training—streamline algorithm iteration, drive robot innovation, and unlock new possibilities.
From automated data preprocessing to efficient scene data management and large-scale training—streamline algorithm iteration, drive robot innovation, and unlock new possibilities.
From automated data preprocessing to efficient scene data management and large-scale training—streamline algorithm iteration, drive robot innovation, and unlock new possibilities.

Customer Challenges
Customer Challenges

Manual Data Processing
Scenario Data Management
Long Iteration Cycle
Manual Data Processing
Cumbersome Data Preprocessing
Data transformation, classification, cleaning, and preprocessing involve complex steps, making manual operations extremely time-consuming.
Difficult Data Annotation
Preprocessed data is hard to align accurately with labeled data, impacting downstream tasks.
01
Manual Data Processing
Scenario Data Management
Long Iteration Cycle
Manual Data Processing, Difficult to Automate
Cumbersome Data Preprocessing
Data transformation, classification, cleaning, and preprocessing involve complex steps, making manual operations extremely time-consuming.
Difficult Data Annotation
Preprocessed data is hard to align accurately with labeled data, impacting downstream tasks.
01
Accelerate Algorithm Development
Data Cleaning and Preparation
Automated Preprocessing Workflow
New data automatically triggers preprocessing conditions, standardizing data formats in a pipeline to streamline transformation, classification, cleaning, and formatting.
Integrated Support for Efficiency
The platform enables seamless integration to enhance efficiency and quality in data processing tasks such as annotation.




Data and Edge Case Management
Efficient Data Classification and Management
Leverage hierarchical categorization and tagging tools for structured data classification and fast retrieval.
Semantic Analysis and Extraction
Utilize workflows and visual analytics to automatically parse data semantics, identify root causes, and enrich data insights.
Algorithm Testing and Training
Rapid Testing and Simulation
The platform enables quick data and software version preparation for large-scale testing and simulation, allowing real-time algorithm adjustments.
Scalable Training Capabilities
On-demand training clusters optimize computational resources, significantly improving algorithm performance and shortening version update cycles.
Continuous Performance Monitoring
Post-deployment, algorithm performance is continuously monitored to ensure stability and reliability, proactively detecting and resolving potential issues.

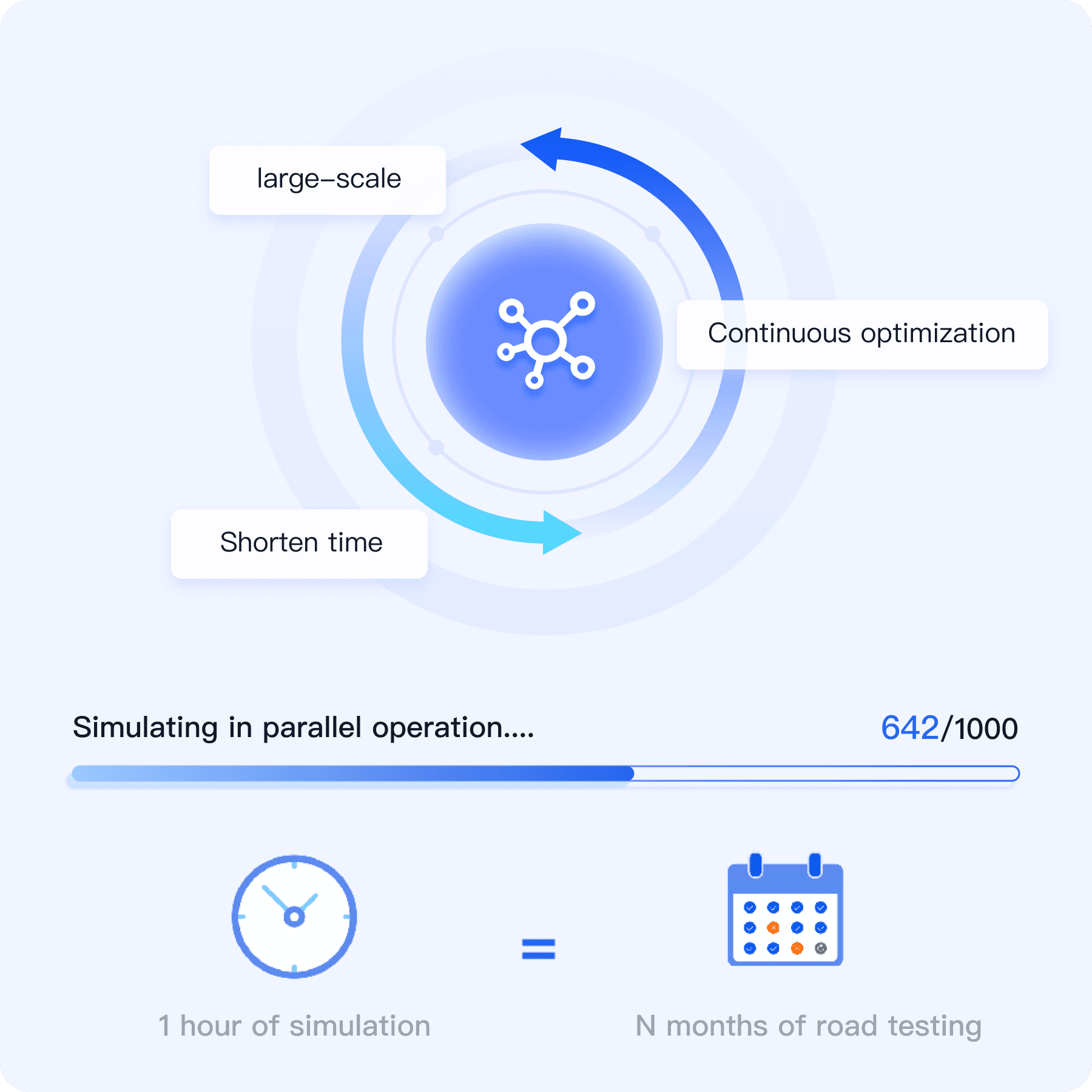

Customer Benefits
Revolutionary Simplification of Data Preprocessing
Workflow automation boosts data processing speed by 100x, significantly reducing manual effort.
Comprehensive Scenario Dataset Management
Flexible classification and management tools enable efficient retrieval and organization of scenario data.
Rapid Acceleration of Algorithm Iteration
Distributed computing frameworks and high-performance clusters accelerate algorithm deployment by 12x, driving innovation forward.
Customer Benefits
Revolutionary Simplification of Data Preprocessing
Workflow automation boosts data processing speed by 100x, significantly reducing manual effort.
Comprehensive Scenario Dataset Management
Flexible classification and management tools enable efficient retrieval and organization of scenario data.
Rapid Acceleration of Algorithm Iteration
Distributed computing frameworks and high-performance clusters accelerate algorithm deployment by 12x, driving innovation forward.
Customer Benefits
Revolutionary Simplification of Data Preprocessing
Workflow automation boosts data processing speed by 100x, significantly reducing manual effort.
Comprehensive Scenario Dataset Management
Flexible classification and management tools enable efficient retrieval and organization of scenario data.
Rapid Acceleration of Algorithm Iteration
Distributed computing frameworks and high-performance clusters accelerate algorithm deployment by 12x, driving innovation forward.

Why Choose coScene?
When it comes to flexibility in data processing and storage, choosing the right deployment approach is crucial. coScene offers multiple deployment options, including fully managed, multi-tenant, single-tenant, hybrid, and on-premises solutions to meet diverse customer needs.
Whether you're a startup, an SME, or a large enterprise, we provide flexible, secure, and reliable deployment solutions.
Why Choose coScene?
When it comes to flexibility in data processing and storage, choosing the right deployment approach is crucial. coScene offers multiple deployment options, including fully managed, multi-tenant, single-tenant, hybrid, and on-premises solutions to meet diverse customer needs.
Whether you're a startup, an SME, or a large enterprise, we provide flexible, secure, and reliable deployment solutions.
Why Choose coScene?
When it comes to flexibility in data processing and storage, choosing the right deployment approach is crucial. coScene offers multiple deployment options, including fully managed, multi-tenant, single-tenant, hybrid, and on-premises solutions to meet diverse customer needs.
Whether you're a startup, an SME, or a large enterprise, we provide flexible, secure, and reliable deployment solutions.
Customer Challenges

Manual Data Processing, Difficult to Automate
01
Cumbersome Data Preprocessing
Data transformation, classification, cleaning, and preprocessing involve complex steps, making manual operations extremely time-consuming.
Difficult Data Annotation
Preprocessed data is hard to align accurately with labeled data, impacting downstream tasks.

Challenges in Scenario Data Management
02
Diversity and Storage Challenges
Scenario data comes from various sources with inconsistent formats and structures, lacking efficient storage and retrieval mechanisms.
Burden of Data Updates and Maintenance
Scenario data evolves continuously, making regular updates and dataset maintenance a daunting task.
Version Tracking and Rollback Challenges
Preprocessed data lacks clear version tracking, making it difficult to revert to previous versions when errors occur.
Large-Scale Data and Access Limitations
Massive scenario data is stored on shared drives, restricted by network conditions, leading to redundant downloads and inefficiencies.
Long Algorithm Iteration Cycles
03
Resource-Intensive Algorithms
Large-scale algorithm models demand extensive computing resources.
Time-Consuming Testing
Sequential algorithm testing on large-scale scenario data requires significant time.
Versioning and Optimization Issues
Algorithm versions and test results lack clear correspondence, making it difficult to compare historical differences and optimize effectively.
Limited Scalability in Data Processing
Large-scale data processing is often constrained by memory limitations, hindering scalability.
Manual Data Processing, Difficult to Automate
01
Cumbersome Data Preprocessing
Data transformation, classification, cleaning, and preprocessing involve complex steps, making manual operations extremely time-consuming.
Difficult Data Annotation
Preprocessed data is hard to align accurately with labeled data, impacting downstream tasks.
Challenges in Scenario Data Management
02
Diversity and Storage Challenges
Scenario data comes from various sources with inconsistent formats and structures, lacking efficient storage and retrieval mechanisms.
Burden of Data Updates and Maintenance
Scenario data evolves continuously, making regular updates and dataset maintenance a daunting task.
Version Tracking and Rollback Challenges
Preprocessed data lacks clear version tracking, making it difficult to revert to previous versions when errors occur.
Large-Scale Data and Access Limitations
Massive scenario data is stored on shared drives, restricted by network conditions, leading to redundant downloads and inefficiencies.
Long Algorithm Iteration Cycles
03
Resource-Intensive Algorithms
Large-scale algorithm models demand extensive computing resources.
Time-Consuming Testing
Sequential algorithm testing on large-scale scenario data requires significant time.
Versioning and Optimization Issues
Algorithm versions and test results lack clear correspondence, making it difficult to compare historical differences and optimize effectively.
Limited Scalability in Data Processing
Large-scale data processing is often constrained by memory limitations, hindering scalability.
Manual Data Processing, Difficult to Automate
01
Cumbersome Data Preprocessing
Data transformation, classification, cleaning, and preprocessing involve complex steps, making manual operations extremely time-consuming.
Difficult Data Annotation
Preprocessed data is hard to align accurately with labeled data, impacting downstream tasks.
Challenges in Scenario Data Management
02
Diversity and Storage Challenges
Scenario data comes from various sources with inconsistent formats and structures, lacking efficient storage and retrieval mechanisms.
Burden of Data Updates and Maintenance
Scenario data evolves continuously, making regular updates and dataset maintenance a daunting task.
Version Tracking and Rollback Challenges
Preprocessed data lacks clear version tracking, making it difficult to revert to previous versions when errors occur.
Large-Scale Data and Access Limitations
Massive scenario data is stored on shared drives, restricted by network conditions, leading to redundant downloads and inefficiencies.
Long Algorithm Iteration Cycles
03
Resource-Intensive Algorithms
Large-scale algorithm models demand extensive computing resources.
Time-Consuming Testing
Sequential algorithm testing on large-scale scenario data requires significant time.
Versioning and Optimization Issues
Algorithm versions and test results lack clear correspondence, making it difficult to compare historical differences and optimize effectively.
Limited Scalability in Data Processing
Large-scale data processing is often constrained by memory limitations, hindering scalability.
Manual Data Processing, Difficult to Automate
01
Cumbersome Data Preprocessing
Data transformation, classification, cleaning, and preprocessing involve complex steps, making manual operations extremely time-consuming.
Difficult Data Annotation
Preprocessed data is hard to align accurately with labeled data, impacting downstream tasks.
Challenges in Scenario Data Management
02
Diversity and Storage Challenges
Scenario data comes from various sources with inconsistent formats and structures, lacking efficient storage and retrieval mechanisms.
Burden of Data Updates and Maintenance
Scenario data evolves continuously, making regular updates and dataset maintenance a daunting task.
Version Tracking and Rollback Challenges
Preprocessed data lacks clear version tracking, making it difficult to revert to previous versions when errors occur.
Large-Scale Data and Access Limitations
Massive scenario data is stored on shared drives, restricted by network conditions, leading to redundant downloads and inefficiencies.
Long Algorithm Iteration Cycles
03
Resource-Intensive Algorithms
Large-scale algorithm models demand extensive computing resources.
Time-Consuming Testing
Sequential algorithm testing on large-scale scenario data requires significant time.
Versioning and Optimization Issues
Algorithm versions and test results lack clear correspondence, making it difficult to compare historical differences and optimize effectively.
Limited Scalability in Data Processing
Large-scale data processing is often constrained by memory limitations, hindering scalability.
Accelerate Algorithm Development
Data Cleaning and Preparation
Automated Preprocessing Workflow
New data automatically triggers preprocessing conditions, standardizing data formats in a pipeline to streamline transformation, classification, cleaning, and formatting.
Integrated Support for Efficiency
The platform enables seamless integration to enhance efficiency and quality in data processing tasks such as annotation.
Data and Edge Case Management
Efficient Data Classification and Management
Leverage hierarchical categorization and tagging tools for structured data classification and fast retrieval.
Semantic Analysis and Extraction
Utilize workflows and visual analytics to automatically parse data semantics, identify root causes, and enrich data insights.
Algorithm Testing and Training
Rapid Testing and Simulation
The platform enables quick data and software version preparation for large-scale testing and simulation, allowing real-time algorithm adjustments.
Scalable Training Capabilities
On-demand training clusters optimize computational resources, significantly improving algorithm performance and shortening version update cycles.
Continuous Performance Monitoring
Post-deployment, algorithm performance is continuously monitored to ensure stability and reliability, proactively detecting and resolving potential issues.
Accelerate Algorithm Development
Data Cleaning and Preparation
Automated Preprocessing Workflow
New data automatically triggers preprocessing conditions, standardizing data formats in a pipeline to streamline transformation, classification, cleaning, and formatting.
Integrated Support for Efficiency
The platform enables seamless integration to enhance efficiency and quality in data processing tasks such as annotation.
Data and Edge Case Management
Efficient Data Classification and Management
Leverage hierarchical categorization and tagging tools for structured data classification and fast retrieval.
Semantic Analysis and Extraction
Utilize workflows and visual analytics to automatically parse data semantics, identify root causes, and enrich data insights.
Algorithm Testing and Training
Rapid Testing and Simulation
The platform enables quick data and software version preparation for large-scale testing and simulation, allowing real-time algorithm adjustments.
Scalable Training Capabilities
On-demand training clusters optimize computational resources, significantly improving algorithm performance and shortening version update cycles.
Continuous Performance Monitoring
Post-deployment, algorithm performance is continuously monitored to ensure stability and reliability, proactively detecting and resolving potential issues.
Unlock Data Potential, Build the Data Flywheel


Unlock Data Potential
Unlock Data Potential, Build the Data Flywheel
contact@spatio.us
© 2025 Spatious Inc.
contact@spatio.us
© 2025 Spatious Inc.
contact@spatio.us
© 2025 Spatious Inc.